
Why Your LLM Prompts Should Match Your Content Language
Matching LLM prompt language to content language isn't just good practice, it's measurably better. Learn why defaulting everything to English costs more and delivers worse results, with real examples from building FacetScore's multilingual sentiment analysis system.


Keeping ahead of technology is a challenging, but fun part of being an engineer in this industry. While I don't write code as much as I would like to these days (except through my company), I do still try to keep my skills sharp and useful.
To this end, I've been working a lot with Large Language Models (LLMs), RAG, Sentiment Analysis and a whole bunch of statistical maths that I've not touched since Uni. All for my company's project, FacetScore.
One thing that's struck me as kind of funny with all this new tech is how we've managed to take a logical and repeatable process of software development, and through LLMs and the magic of maths, made what should be anathema, a non-deterministic random text generator.
This is pretty cool and leads to some interesting applications, but it starts to break down when you need to apply these tools and technologies to read a hotel review written by a drunk salaryman in Japanese.
How do I know? I built FacetScore, a business intelligence tool that reads reviews on travel sites and social media to help hospitality businesses improve their customer service. When your product needs to extract sentiment from reviews written in Japanese, Korean, Chinese, English, and everything in between, you quickly learn what works and what doesn't.
This post covers lessons learned from building a multilingual sentiment analysis system, backed by recent research. I'll use FacetScore as the real-world example throughout to keep things concrete.
The topics I cover here are specifically useful for anyone trying to extract semantic information from unstructured content. My use case was business reviews, but these principles apply equally to resumes, product feedback, support tickets, social media posts, or pretty much any text data where language matters.
The English Default Trap
It seems almost standard for everyone to write their prompts in English and to translate any content incoming to the LLM into English since that's "what the model expects".
On the surface, this seems like it would be a good idea. For sure, the majority of the corpus that these models have trained on is in English, so you'll get better results, right?
Well, it turns out, no.
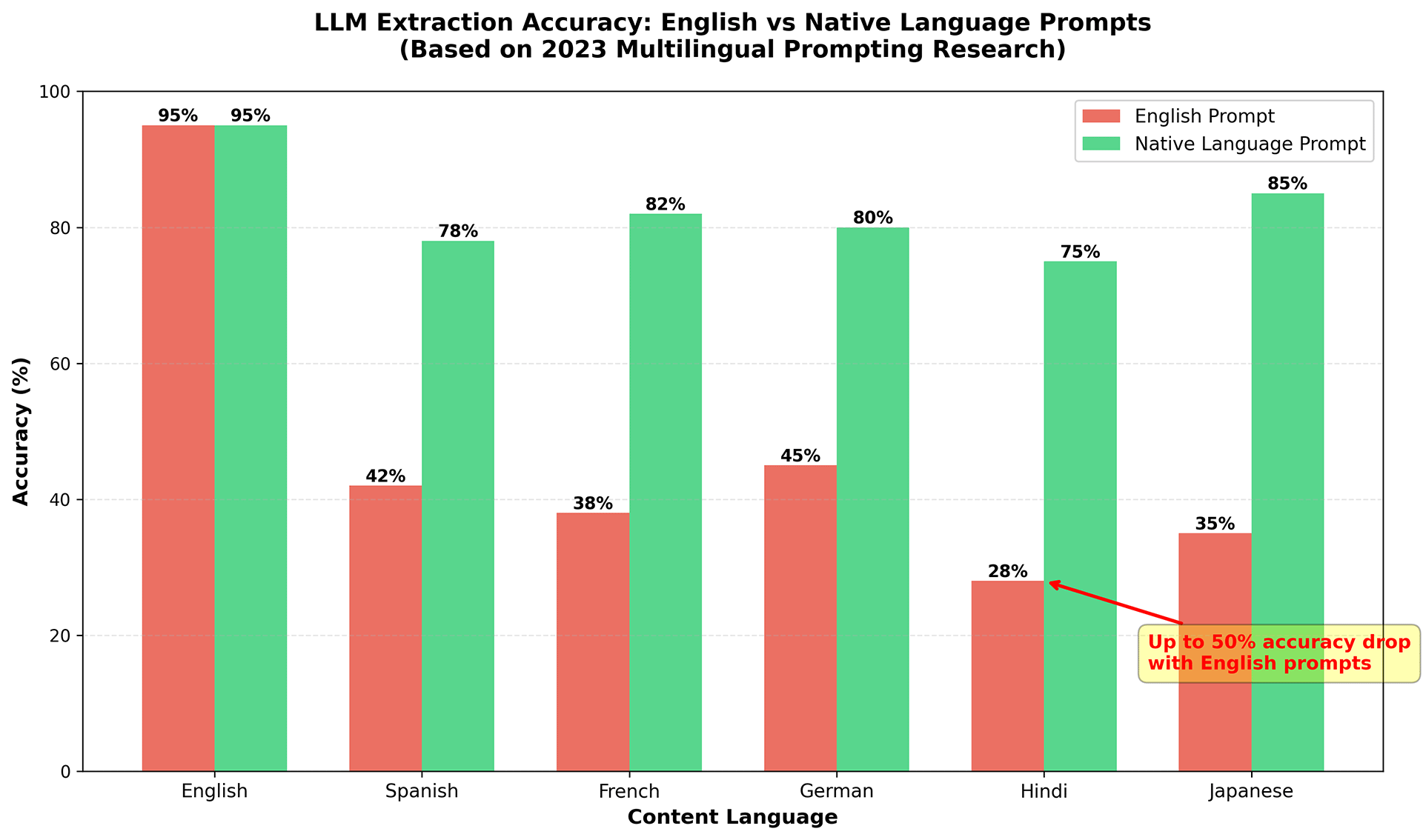
A comprehensive 2025 study [2] across 35 languages examined extraction tasks and found that matching prompt language to content language consistently outperforms the "translate everything to English" approach.
The assumption that using English prompts is better for extracting data in any language isn't just wrong; it's measurably worse. This is especially true when you are processing content and generating output in the same (non-English) language.
There's an important caveat though: automated translation of prompts doesn't work well. Research from 2023 [1] found that machine-translated prompts often fell below 50% accuracy. This means you can't just run your English prompts through Google Translate, or you'll get even worse results.
So the bottom line is that you should match your prompt language to your content language, and have a human being who is ideally a native speaker to create those prompts.
A closer look at how language mismatches between Prompts and Content cause issues
To understand why matching languages makes such a difference, we need to look at what's happening inside the LLM.
It turns out that the performance degradation doesn't just come from translating content. Even when you keep the original language content intact, using an English prompt to process Japanese text creates a cross-lingual mismatch that hurts accuracy.
Research on cross-lingual representation [3] shows that LLMs produce more divergent and less accurate responses when they have to bridge between language-specific semantic spaces. In practical terms: an English prompt trying to extract content from Japanese text forces the model to operate across two separate semantic spaces rather than working within a single, coherent representation.
Think of this like trying to count coins while someone else is shouting numbers at you. You can still perform the task, but it is slower and takes more effort on your part. There's also an increased risk of making a mistake and having to start again.

This means you're taking a double hit:
- The model's internal representations are less aligned across languages
- The extraction task itself becomes harder because the prompt and content "speak different languages" internally
For FacetScore, this wasn't just theoretical, it showed up immediately in production.
A worked example for hotel reviews in FacetScore
My initial implementation of content extraction in FacetScore used this "English First" approach. The naive version provided a "working" prototype, but only after repeated testing did the accuracy problems start to show.
First, for full context, here's what this initial version of FacetScore used an LLM for:
- For each "Facet" being tracked, extract relevant content from the review along with broader context to justify the selection
- Estimate the sentiment of extracted items (used later to double-check sentiment analysis models)
- Extract general keywords that could summarize the review from a curated list of 128 options
The problem revealed itself when processing this short review of a Tokyo hotel:
「サービスはまあまあでした。部屋は普通です。」
("Service was OK. Room was fine.")
With the English prompt, the system classified this as neutral or slightly positive, and assigned tags based on that interpretation.
What it missed was the nuance of Japanese language. In Japanese, "まあまあ" (maa maa) and "普通" (futsuu) are polite ways of expressing disappointment. A satisfied Japanese guest would use words like "良い" (yoi - good) or "素晴らしい" (subarashii - wonderful). When they say "まあまあ," they're being diplomatic about their dissatisfaction.
Switching to a Japanese prompt correctly captured this nuance, treated it as negative feedback, and chose more appropriate tags from the list.
This wasn't just an edge case. Across our test dataset of Japanese reviews, switching to language-matched prompts improved classification accuracy significantly. The same pattern emerged for Korean, Taiwanese Chinese, and Thai; each with their own cultural markers of polite negativity that English prompts consistently missed.
While we have our own embedded data and other augmentations to enhance LLM-based extraction, the business impact of this mismatch was real and measurable. FacetScore was missing important nuance and context by forcing the LLM to use semantic bridging to build understanding of the content.
We also noticed English prompts took between 25% and 35% longer to process non-English content compared to native language prompts. Research on cross-lingual processing supports this [4]; models working across semantic spaces require more computational steps than those operating within a single language space.
We tested with 1000 reviews, using a 0 temperature and the same general prompt outline and output requirements. The prompts were written by native speakers of the languages in question.
In other words: We were spending more money to get worse results.
Improving extraction in FacetScore
So, how did we fix the extraction in FacetScore? The short answer is that there isn't a real way to "fix" this; ultimately, even if we solve prompt problems, we're still at the mercy of LLMs being essentially non-deterministic text generators.
We can, however, improve things significantly, and this is how we went about it:
- Created native-language prompts for each Facet extraction in each of our primarily supported languages. For unsupported languages, we still use the English prompt, but we're now more aware of the limitations and potential accuracy issues.
- Implemented fast language detection using a small model based on
papluca/xlm-roberta-base-language-detectionfor its quick speed and broad language support. This ensures we're processing content with the correct prompt language. At most, this adds 2ms to the process, and is more than made up for by the general execution time savings. - Localized our classification tags, rendering them in the native prompt language with mappings to make them comparable across languages.
- Set temperature to 0 to reduce the likelihood of the LLM hallucinating or making things up. This isn't here to improve the prompt match, but it's important to keep the results deterministic between runs. When testing or debugging, we want to verify the prompt, not the model's mood.
- Enforced structured JSON Schema for data output, with fallback thresholds for when content either can't be extracted or isn't suitable. Combined with the 0 temperature, this ensures consistent and repeatable output, regardless of the source data.
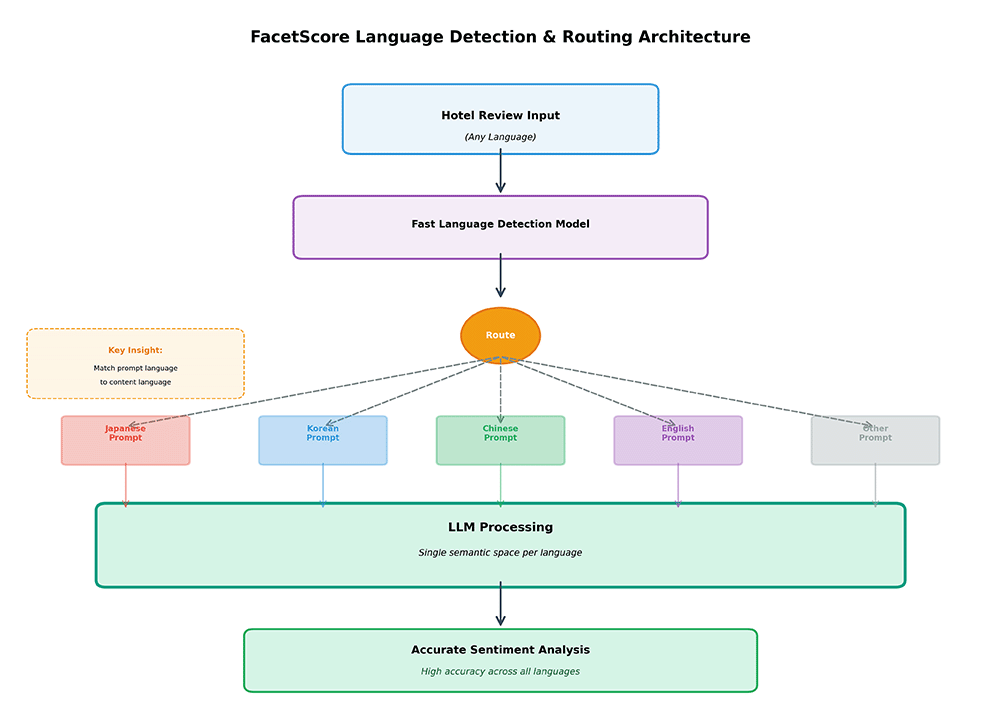
The result? Classification accuracy improved across the board, processing time decreased by up to 35%, and we eliminated an entire class of bugs related to cross-language extraction failures. Every language tested saw double-digit accuracy gains after prompt matching.
So what is the lesson here?
If you're building any system that extracts, classifies, or analyzes multilingual text, the lesson is simple: match your prompt language to your content language.
This isn't just about accuracy; it's about:
- Cost efficiency: 25-30% faster processing means lower infrastructure bills
- Better user outcomes: Capturing cultural nuance means better business decisions
- Fewer bugs: Eliminating cross-language extraction failures reduces maintenance
The implementation is straightforward:
- Add fast language detection
- Create prompts in your target languages
- Route content to the appropriate prompt
Of course, it requires upfront work creating multiple prompt versions. However, given the drastic improvements in accuracy and the very real cost and time savings to the project in the wild, it's arguably extra work that should be just done, now that you know there is a better way.
If you're working with LLMs on multilingual data, don't fall into the English Default Trap. Your accuracy, your users, and your infrastructure bill will thank you.
Footnotes
- [1]: Multilingual Prompting in LLMs: Investigating the Accuracy and Performance (February 2023)
International Journal of Scientific Research in Engineering and Management
https://www.researchgate.net/publication/386436285 - [2]: Beyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs (February 2025)
https://arxiv.org/html/2502.09331v1 - [3]: Language-Specific Latent Process Hinders Cross-Lingual Performance (September 2025) https://arxiv.org/html/2505.13141
- [4]: Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs (February 2025) https://arxiv.org/html/2502.14830v1
If you want to learn more about FacetScore, you can read more about it on the Arkilon Blog, or contact the team to arrange a demo.
Further reading and related content
If you're looking to take a more deeper dive into the literature, check out these papers.
Core Multilingual Prompting Research
- Multilingual Prompting Performance Degradation
Multilingual Prompting in LLMs: Investigating the Accuracy and Performance (2023)
International Journal of Scientific Research in Engineering and Management
https://www.researchgate.net/publication/386436285 - Selective Pre-translation for Extractive Tasks
Beyond English: The Impact of Prompt Translation Strategies across Languages and Tasks in Multilingual LLMs (2025)
https://arxiv.org/html/2502.09331v1 - Multilingual Performance Quantification
Quantifying Multilingual Performance of Large Language Models Across Languages (2024)
https://arxiv.org/html/2404.11553v1 - Comprehensive Survey of Multilingual LLMs
A survey of multilingual large language models (2025)
Patterns (Cell Press)
https://www.cell.com/patterns/fulltext/S2666-3899(24)00290-3 - Multilingual Prompt Engineering Survey
Multilingual Prompt Engineering in Large Language Models: A Survey Across NLP Tasks (2025)
https://arxiv.org/abs/2505.11665
Cross-Lingual Representation Research
- Language-Specific Latent Processes
Language-Specific Latent Process Hinders Cross-Lingual Performance (2025)
https://arxiv.org/html/2505.13141 - Cross-Lingual Semantic Alignment
Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs (2025)
https://arxiv.org/html/2502.14830v1 - Knowledge Representation Sharing
Beneath the Surface of Consistency: Exploring Cross-lingual Knowledge Representation Sharing in LLMs (2024)
https://arxiv.org/html/2408.10646v1 - Cross-Lingual In-Context Pre-training
Enhancing LLM Language Adaption through Cross-lingual In-Context Pre-training (2025)
https://arxiv.org/html/2504.20484
Sentiment Analysis & Extraction Applications
- Multilingual Sentiment Analysis Challenges
Challenges & Methods for Multilingual Sentiment Analysis (2024)
AIMultiple Research
https://research.aimultiple.com/multilingual-sentiment-analysis/ - Cross-Lingual Sentiment Analysis with LLMs
A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM (2024)
Scientific Reports, Nature
https://www.nature.com/articles/s41598-024-60210-7 - Comparative LLM Sentiment Analysis
ChatGPT vs Gemini vs LLaMA on Multilingual Sentiment Analysis (2024)
https://arxiv.org/html/2402.1715 - State-of-the-Art Multilingual Sentiment Review
Multilingual Sentiment Analysis: State of the Art and Independent Comparison of Techniques (2016)
Cognitive Computation, Springer
https://link.springer.com/article/10.1007/s12559-016-9415-7
Additional Resources
- Awesome Multilingual LLM Repository
GitHub compilation of multilingual LLM research and datasets
https://github.com/LightChen233/Awesome-Multilingual-LLM